※언어 종류
대표적인 Managed 언어 : *Java, Python, C# 등
대표적인 Unmanaged 언어 : *C, C++, Assembly
대표적인 스크립트 언어: JavaScript, *Python,Ruby
1.Managed 언어
(참조:
https://ko.wikipedia.org/wiki/%EA%B3%B5%ED%86%B5_%EC%96%B8%EC%96%B4_%EB%9F%B0%ED%83%80%EC%9E%84,http://guslabview.tistory.com/56)
:Runtime에 의해 관리되는(Managed) 언어이다.
*CLR(Common Language Runtime) - 공통 언어 런타임
1)VB.NET&C#의 소스코드 -> (컴파일) -> IL 바이트코드(dll & exe) ----컴파일 시간(빌드)
2)바이트코드-> (CLR) -> 네이티브코드(기계어) ----런타임(실행중)
CLR은 Runtime 시에 보안,메모리관리(garbage collection),쓰레드를 지속적으로 관리해준다.

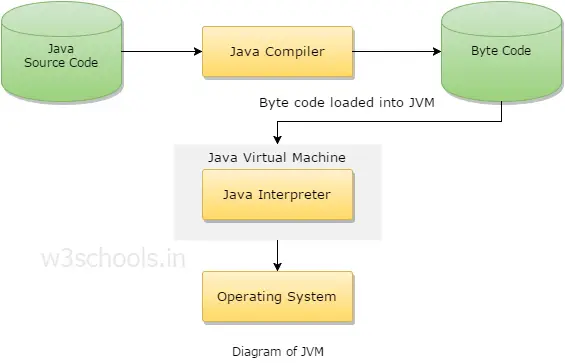
*JVM(Java Virtual Machine) - 자바 가상 머신
1)JAVA의 소스코드(.java) -> (컴파일) -> IL 바이트코드(.class) ----컴파일 시간(빌드)
2)바이트코드-> (JVM) -> 네이티브코드(기계어) ----런타임(실행중)
JVM은 JAVA가 OS에 구애받지 않고 재사용을 가능하게 해준다. 그리고 가장 중요한 메모리관리, Garbage collection을 수행한다.
*IL(Intermediate Language) - 중간언어
*JIT 컴파일(just-in-time compilation) 또는 동적 번역(dynamic translation)은 프로그램을 실제 실행하는 시점에 기계어로 번역하는 컴파일 기법이다.
-장점
1)JIT 컴파일로 인한 추가 CPU/메모리 부담을 없애고
2)컴파일된 기계어를 여러 프로세스에서 공유할 수 있으며
3)애플리케이션 시작 시간을 단축하는 장점이 있다.
2.Unmanaged 언어
Unmanaged 언어를 컴파일하면 Native code(기계어) 형태의 exe파일이 만들어짐.
Unmanaged 언어는 Managed언어와 다르게 중간언어(IL)를 만들지 않기때문에 속도에 대한 장점을 가지지만 확장성의 한계를 가짐.(다른프로세서 기반에서 똑같은 코드를 실행하려면 새롭게 컴파일을 해야하기때문이다.)
3.스크립트 언어
= 수정이 빈번하게 발생하면 수정 후 일일이 컴파일을 다시 해야 한다. 수정이 빈번하게 발생하는 부분은 소스코드를 한줄 한줄 읽어 바로바로 실행하는 인터프리터 방식이 상당히 유리하다. 스크립트 언어는 이런 부분에 사용하기 위해 나온 것이다.
*인터프리터(해석기)는 프로그래밍 언어의 소스 코드를 바로 실행하는 컴퓨터 프로그램 또는 환경을 말한다.
-장점-
컴파일 과정을 거치지 않고 실시간으로 텍스트를 분석하며 실행된다.
컴파일 언어보다 단순하고 쉬운 문법을 사용하는 경우가 많다.
컴파일 언어보다 실행 속도가 느리다.
※프로그램과 프로세스
프로그램:하드디스크에 저장된 파일중 실행가능한 파일
프로세스:메모리에 로딩된 프로그램 / 현재 실행중인 프로그램
1)대화형 프로세스
:프로그램과 정보를 주고받는 동안 프로세스는 포그라운드에서 실행된다.
2)배치 프로세스
:일련의 작업을 몰아서 특정 시각에 실행 시키는 프로세스
3)데몬 프로세스 (리눅스 - 데몬 / 윈도우 - 서비스)
:백그라운드 상태에서 계속 실행되는 서버 프로세스입니다.
※malloc과 new 차이점(힙영역에 메모리할당됨)
1)malloc -> int* ptr = (int*)malloc(sizeof(int)*4)
-malloc은 반환값이 void* 라서 형변환을 해줘야함
-할당할 메모리의 크기를 알아야함
-메모리동적할당만 가능
-realloc 으로 메모리 재할당이 가능함
2)new -> int* ptr = new int
-할당하려는 데이터타입을 포인터로 반환
-할당할 메모리의 크기를 몰라도됨
-메모리동적할당,초기값 셋팅가능
-재메모리 재할당이 불가능함
※리눅스 쉘과 커널
USER -> 쉘 -> 커널 -> 하드웨어
쉘 - 명령어 해석기
커널 - 하드웨어 조작기
※URI,URL 차이점
:URI 는 URL 과 URN을 포함하는 상위개념이다.

URI : Uniform Resource Identifier (통합자원식별자)
URL : Uniform Resource Locator (통합자원위치)
URN : Uniform Resource Name (통합자원이름
URI = URL+URN
-예제-
URI : https://search.naver.com/search.naverwhere=nexearch&sm=top_hty&fbm=1&ie=utf8&query=uri
: 가변적-다른결과 ex) 동물/?type=고양이
URL : https://www.naver.com/test.jpg/ :고정적-같은결과 ex)고양이
URN : urn:uuid:6e8bc430-1c2a-12d9-5775-0100700c9a66 (uuid나 isbn를 해석가능한 프로그램이 있어야 동작함)
※메모리(32bit,64bit)
:컴퓨터 32bit(x86) 와 64bit(x64) 다른점 (CPU가 관리할수 있는 메모리 용량)
32bit는 2³² => 4294967296(byte) => 가상공간 4GB =>약 2G (유저메모리&유저모드)와 약 2G (시스템 메모리&커널모드)로 할당이 제한되어 있습니다.
그래서 32비트 운영체제는 메모리 주소가 16진수 8자리로 표현한다.
0x00000000 부터 0xFFFFFFFF
ex)0x001af8a0
64bit는 2⁶⁴ => 18,446,744,073,709,551,616(byte) => 16EB =>
가상공간16TB 사용가능 이론상으로 최대 16EB까지 사용가능하지만 메모리용량이 너무 커 비효율적이다.
(8TB (유저메모리&유저모드)와 8TB (시스템 메모리&커널모드)로 할당이 제한되어 있습니다.)
그래서64비트 운영체제는 메모리 주소가 16진수 16자리로 표현한다.
0x0000000000000000 부터 0xFFFFFFFFFFFFFFFF
ex)0x001af8a0121bc1b7
바이트(byte)란 컴퓨터가 처리하는 정보의 기본단위로, 하나의 문자를 표현하는 단위이다. 8bit를 묶어서 1byte로 부른다.
워드는 컴퓨터가 한번에 전송하거나 처리할 수 있는 정보량의 단위를 의미합니다. 기기에 따라서 워드단위는 바뀌게 됩니다.
예를 들어 32bit 윈도우를 사용하는 PC라면 1워드=32bit 이지만, 64bit 윈도우를 사용하는 PC에서는
1워드=64bit 가 된다.
1bit = 0과1을 표현
1B = 8bit
1KB = 1024B
1MB = 1024KB
1GB = 1024MB
1TB = 1024GB
1PB = 1024TB
1EB = 1024PB
참고: https://shaeod.tistory.com/578
※메모리의구조
:프로그램이 실행되려면 메모리에 로드되어야 한다. 프로그램이 운영체제로 부터 할당받는 메모리공간은 4개로 나뉜다.
1.코드(Code)영역
프로그램 내부에 작성된 소스코드가 코드영역에 들어간다. 프로그램이 끝날때 까지 정보를 계속 가지고 있는다.
2.메모리(Memory)영역
전역변수나 *Static변수가 메모리영역에 들어간다. 프로그램이 끝날때 까지 정보를 계속 가지고 있는다.
*Static변수 = 단 한번만 초기화를 하는 변수, 이후에 초기화를 해도 반영되지 않는다.
3.힙(Heap)영역
런타임때 크기가 결정된다.
C언어는 malloc으로 메모리를 할당할때 힙영역에 들어간다. / free로 해제
C++은 New로 메모리를 할당할때 힙영역에 들어간다. / delete로 해제
JAVA나 C#은 New로 메모리를 할당할때 힙영역에 들어간다. / *GC(Garbage collection)에 의해 메모리가 해제된다.
*GC(Garbage collection)이란
메모리 관리기법중 하나로, 프로그램이 동적으로 할당했던 메모리 영역 중에서 필요없게 된 영역을 해제하는 기능이다.
4.스택(Stack)영역
지역 변수, 매개 변수, 리턴 값 등등이 저장된다.
함수 호출 시 생성되고, 함수가 종료되면 시스템에 반환된다.
프로그램이 자동으로 사용하는 임시 메모리 영역이다.
또한 이름에서 보듯이 Stack 자료구조를 이용해 구현한 것 같다.
컴파일 시에 크기가 결정된다. LIFO구조이다.(Last In First Out)
※MVC패턴
:MVC패턴이란 모델 - M(Model), 뷰 - V(View), 컨트롤 - C(Controller) 컴퓨터 소프트웨어 개발의 구조적 패턴이다.
1.자바 기준
jsp는 여기서 V(View)에 해당한다. V(View)를 제어하기 위한 C(Controller)에 JAVA가 사용된다.
2.안드로이드 기준
xml은 여기서 V(View)에 해당한다. V(View)를 제어하기 위한 C(Controller)에 JAVA가 사용된다.
※UI/UX
1.UI
UI란 User Interface 사용자가 제품을 어떤 방식으로 이용하도록 만드냐를 디자인 하는것이다.
2.UX
UX란 User eXperience 지난 수십년간 사용자들이 '이런 환경&구조로 구성되어있는 앱/웹사이트가 사용하기 편리하더라'라는 데이터를 토대로 설계를 하면 설계에 도움되는 부분이 있다.
※안드로이드 생명주기
:안드로이드를 개발할때 액티비티(Acitivity)의 생명주기(Life Cycle)가 어떻게 돌아가는지 알고있어야 손쉽게 작업할 수 있다.

onCreate() -> onStart() -> onResume() -> onPause() -> onStop() -> onDestroy()
onRestart() ->
onCreate() - 액티비티 생성 (액티비티가 생성되리때 호출됨)
onStart() - 액티비티 시작 (액티비티가 사용자에게 보여지기 직전에 호출됨)
onResume() - 액티비티 다시시작 (사용자가 현재 액티비티를 다시 불렀을때)
onPause() - 액티비티 일시정지 (다른 액티비티가 앞에서 돌아가고 있을때)
onStop() - 액티비티 정지 (액티비티가 더이상 사용자에게 보여지지 않을때 호출됨)
onDestroy() - 액티비티 제거 (액티비티가 소멸될때 호출됨)
※오버로딩(Overloading),오버라이딩(Overriding) 차이점
1.오버로딩(적재)
:같은 클래스내에서 서로다른 파라메터를 받는, 같은 이름의 메서드를 사용하는것
2.오버라이딩(재정의)
:부모로 부터 상속받은 이후 메서드를 재정의 하고싶을때 사용한다.
*오버로딩과 오버라이딩 성립조건

※객체지향
객체(Object)는 소프트웨어 세계에 구현할 대상이고, 이를 구현하기 위한 설계도가 클래스(Class)이며, 이 설계도에 따라 소프트웨어 세계에 구현된 실체가 인스턴스(Instance)이다.
필드(Field):클래스안의변수(저장)
메소드(Method):클래스안의함수(동작)
인스턴스(Instance):클래스로부터 만들어진객체
클래스(Class):객체를 정의한것(설계도) // 클래스 = *구조체+메소드
메시지(Message):메소드에 접근할때 사용하는것 (형식:객체.메소드명(인자))
*구조체(Struct) = 하나 이상의 변수를 그룹 지어서 새로운 자료형을 정의하는 것
※해시함수
※해시함수
해시함수(hash function)란 데이터의 효율적 관리를 목적으로 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수입니다. 이 때 매핑 전 원래 데이터의 값을 키(key), 매핑 후 데이터의 값을 해시값(hash value), 매핑하는 과정 자체를 해싱(hashing)라고 합니다.
해시함수는 해쉬값의 개수보다 대개 많은 키값을 해쉬값으로 변환(many-to-one 대응)하기 때문에 해시함수가 서로 다른 두 개의 키에 대해 동일한 해시값을 내는 해시충돌(collision)이 발생하게 됩니다.
해시 테이블의 공간 사용률이 70%~80%에 이르면 성능 저하가 나타나기 시작한다. (보통 데이터의 용량의 1.2~1.5크기가 좋다고함)
1)MD5
128비트(2비트4개 ->16진수 * 32개) -> 32자리
2)SHA256
256비트(2비트4개 ->16진수 * 64개) -> 64자리
2)SHA512
512비트(2비트4개 ->16진수 * 128개) -> 128자리
*장단점(참조:https://blog.naver.com/sk2ckr/221387031921)
1)장점
*ISAM(색인순서접근방식)보다 상당히 빠른 검색속도를 지님
데이터에 대한 입력이나 삭제가 용이
검색시간이 데이터의 양과 무관하게 일정하게 유지
2)단점
연속적인 데이터 검색에는 비효율적
디스크 공간이 비효율적으로 사용됨
디스크 공간을 늘리고 재구조화하게 되면 재 검색을 위한 상당시간 소요됨
*버켓 충돌 가능(고정된 길이나 값으로 인한 중복 결과가능)
※멀티프로세스, 멀티스레드 (공통:동시에 두가지 이상의 일을 함)
1.멀티프로세스
1)자신만의 메모리를 가진다.
2)부모-자식관계 환경변수와 프로세스 핸들이 상속가능하지만 결국 독립적인 관계이다.
3)구현이 간편함.
4)병렬 처리 하는만큼 프로세스를 생성해야함.
5)프로세스가 많이 생성될 수록 메모리 사용량 증가.
2.멀티스레드
1)하나의 프로세스가 여러작업을 각각 스레드를 이용하여 동시에 작동 시킬 수 있다.
2)메모리를 공유한다.(code,data,heep),스택은 개별적으로 관리한다
3)구현이 복잡함.
4)프로세스간 통신 *IPC(예:pipe,Message Queue,공유메모리,Semaphore)과 같은 복잡한 과정을 거치지 않아도 되서 효율적인 일처리가능
5)동기화 문제가 발생할 우려가 있어 면밀히 검토해야함.
*IPC(Inter Process Comunicate)종류와 특징 참조:http://jwprogramming.tistory.com/54
!!공유 자원에 동시에 접근할 경우 다양한 문제점이 발생 할 수 있다.이런 상황을 예방하기 위해 "야 우리 동시에 접근 안하는게 어때?"라는 약속이 필요한데 이게 바로 *상호배제이다. 또 *임계영역이란 이런 공유 자원에 접근하는 코드 영역을 의미한다.
3.Critical Section(임계구역)
:공통 영역을 두 개 이상 병렬하는 프로세스 혹은 프로그램이 사용되는 경우에 이 영역을 말한다.
4.상호배제-뮤텍스,세마포어
:공유 불가능한 자원의 동시 사용을 피하기 위해 사용되는 알고리즘이다.
1)뮤텍스 - 일종의 Locking 매커니즘이다. lock을 가진경우에만 공유자원 접근가능, 해제도 lock을 가진사람이 해제
= 이진 세마포어(binary semaphore) 자원이 0과 1을 가지고 있는경우
2)세마포어 - 자원의 수가 여러개일 경우 사용하는 기법이다.(Counting Semaphore), 허용가능한 count 갯수로 보면된다. 예를 들어서 3자리가 있을경우 자리가 꽉차면 접근 불가, 자리가 생기면 접근가능
※재귀함수
:자기자신을 호출하는 함수.
장점 : 코드간소화 // 단점 : 자기자신을 호출할 때마다 메모리가 계속 쌓임(스택 오버플로 가능)
좋은예 : 하노이탑 // 안좋은예 : 피보나치 수열
재귀함수를 호출할 때 마다 *스택영역에 쌓이게된다.
예:Recursive(0) = 1일때
def Recursive(n):
if n==0:
return 0
else
return Recursive(n-1)+1

※UTF-8,UTF-16
(참조:https://terms.naver.com/entry.nhn?docId=5662548&cid=43667&categoryId=43667)
1.UTF-8
:UTF-8은 문자 하나를 표현할때 1Byte단위로 저장할 수 있다.(영문 - 1Byte , 한글 - 3Byte)
자료에 영문이 많을경우 UTF-8이 유리하다.
2.UTF-16
:UTF-16은 문자 하나를 표현할때 2Byte단위로 저장할 수 있다.(영문 - 2Byte , 한글 - 2Byte)
자료에 한글이 많을경우 UTF-16이 유리하다.
※정규식(이메일&전화번호)
:정규식(正規式)은 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어이다.(참조:https://wikidocs.net/4308)
※라이브러리(도서관),프레임워크(틀)
(참조:https://blog.gaerae.com/2016/11/what-is-library-and-framework-and-architecture-and-platform.html)
1.라이브러리(library) - !!메인함수가 없다.
:재사용이 필요한 기능으로 반복적인 코드 작성을 없애기 위해 언제든지 필요한 곳에서 호출하여 사용할 수 있도록 Class나 Function으로 만들어진 것이다. - 내가 가지고 있는 틀에 필요한 기능을 가져다가 사용하는것.(사용자 중심)
예)내가 집을 지을때 문이나 창틀, 장판같은걸 가져다 쓴다고 보면된다. 가져다 쓰는 도구(함수) // jquery(java) 등등
2.프레임워크(framework)
:프레임워크만으로는 실행되지 않으며 기능 추가를 해야 되고 프레임워크에 의존하여 개발해야 되며 프레임워크가 정의한 규칙을 준수해야 한다. - 만들어져 있는 틀에 기능을 추가해서 사용하는것.(프레임워크 중심)
예)아파트에 입주하는데 나는 인테리어만 조금 손 본다면 바로 아파트가 프레임워크 이다. // spring(java),django(python)등등
※접근제한자
private(기본) - 클래스 내부에서만 접근이 가능합니다.
public - 모든 곳에서 해당 멤버로 접근이 가능합니다.
internal - 같은 어셈블리에서만 public으로 접근이 가능합니다.
protected - 파생클래스에서 이 클래스 멤버를 엑세스할 수 있다. (상속받으면 사용가능)
※RDBMS와NO-SQL 차이점
RDBMS(관계형 데이터베이스) ex)Oracle,Mssql,Mysql
No-SQL(Not only SQL:기존의 관계형 데이터베이스랑은 다른 저장방식) ex)Mongo DB
1)No-SQL은 RDBMS와는 달리 데이터 관계를 정의하지 않아도 된다.
2)RDBMS에 비해 훨씬 더 대용량의 데이터를 저장할 수 있다.
3)RDBMS와는 다르게 No-SQL은 데이터 저장소가 분산형 구조이다.
4)RDBMS와는 다르게 스키마가 유동적이다. 필드별로 자료형이 정의되어있지 않다.
※해시테이블 (Hashtable)과 딕셔너리 (Dictionary) 차이
1.해시테이블
1)Non-Generic(유동적)
2)Key와value값 모두 object로 받는다.
3)박싱과 언박싱이 이루어짐
2.딕셔너리
1)Generic(고정적)
2)Key와value값 모두 Type을 입력 받는다.
3)박싱과 언박싱이 이루어지지 않는다.
:고정적인 타입으로 입력받을때는 딕셔너리 타입, 아닐때는 해시테이블을 사용해야한다.
※박싱(Boxing)과 언박싱(Unboxing)
:출처(https://docs.microsoft.com/ko-kr/dotnet/csharp/programming-guide/types/boxing-and-unboxing)
1)박싱(boxing) - 암시적
int i = 123;
object o = i;

2)언박싱(Unboxing) - 명시적
o = 123;
i = (int)o; --캐스팅 필요함

*박싱과 언박싱에는 많은 시간을 소모하기 때문에 되도록이면 제네릭을 사용해서 박싱과 언박싱이 이루어지지 않게 해야하고 어쩔수 없이 사용할 경우에는 언박싱을 할때 캐스팅을 잘 해줘야한다.
※STL정리(배열,Linked List,Vector,Map,Set,Hash)
:STL이란 Standard Template Library로 프로그램에 필요한 자료구조와 알고리즘을 템플릿으로 제공하는 라이브러리를 뜻한다.
1.배열
1)중간값 삽입과 삭제를 하려면 SHIFT를 해줘야 되서 무거움
2)비동기식(동기식 보다 상대적으로 20~30% 빠름)
3)단일 스레드일 경우 사용
2.Linked List
1)중간값 삽입과 삭제가 용이함(포인터변경)
2)항목 접근이 오래걸린다.
3.Vector
1)중간값 삽입과 삭제를 하려면 SHIFT를 해줘야 되서 무거움
2)동기식(비동기식 보다 속도가 느림)
3)다중 스레드일 경우 사용
4.Map(JAVA,C++)
1)key(index), value(data) 한쌍
2)자동정렬된다.
5.Dictionary(.Net, Python),Associative array(Javascript, PHP)
1)key(index), value(data) 한쌍
2)자동정렬이 안된다.
6.Set(집합자료형) - 교집합(Intersection)&합집합(Union) 사용가능
1)중복을 허용하지 않는다.
2)순서가 없다.
※디자인패턴(공부필요!!)
:소프트웨어를 설계할 때 특정 맥락에서 자주 발생하는 고질적인 문제들이 또 발생했을 때 재사용할 할 수있는 훌륭한 해결책
https://gmltjd0911.github.io/Design-Patterns-1/
https://blog.naver.com/2feelus/220642212134
※빌드도구란(Ant,Maven,Gradle)
참조: https://freezboi.tistory.com/39
https://giyatto.tistory.com/100
빌드도구란 소스코드 파일을 실행가능한 소프트웨어 산출물로 만드는 일련의 과정을 말한다.
빌드의 단계 중 컴파일이 포함이 되어 있는데 컴파일은 빌드의 부분집합이라 할 수 있다.
빌드 과정을 도와주는 도구를 빌드 툴이라 한다.
1. ant
- XML , remote repository를 가져올 수 없었음(IVY 도입)
- High flexibility but hard to understand.
2. Maven - 종속적
- XML, remote repository를 가져올 수 있음
- Strong convention but hard to implement custom logic
- 라이브러리들이 서로 종속성을 가지는 경우 XML이 복잡해진다.
- XML은 계층적 데이터를 표현하기에는 좋지만 플로우나 조건부 상황을 표현하기는 힘들다.
- 상속형 (하위 XML이 필요없는 속성도 모두 표기)
3. gradle(안드로이드 스튜디오 빌드툴로 채택) - 독립적
- Groovy, remote repository를 가져올 수 있음
- convention 정책과 함께 custom 빌드 스크립트(groovy) 작성가능
- 멀티플랫폼 프로젝트에도 적합(상위 스크립트, 하위 스크립트 독립적으로 작성)
- 상속이 아닌 주입
- XML대신 Groovy 사용으로 인해 Ant나 Maven으로 작성된 것 보다 훨신 짧으면서 명확하다.
- Build-by-convention을 바탕으로함: 스크립트 규모가 작고 읽기 쉬움
※extend implement 차이점
1.extend(확장)
Extend (Class Name) - 클래스를 확장하겠다.(그대로 사용하거나 @override로 정의된 메소드를 재정의하겠다.)
2.implement(구현)
Implement (Interface Name) - 인터페이스를 구현하겠다
*overriding 와 overloading 차이점
1.overriding은 부모로부터 상속받은 메소드를 재정의하는것
2.overloading은 같은이름의 메소드를 사용하는것 단 매개변수 타입이 다르거나 갯수가 달라야 한다.
class test{
void same(int a){
//내용1
}
void same(String a){
//내용2
}
}.
public interface ExampleInterface{
public void do();
public String doThis(int number);
}
public class sub implements ExampleInterface{
public void do(){
//specify what must happen
}
public String doThis(int number){
//specfiy what must happen
}
}
public class SuperClass{
public int getNb(){
//specify what must happen
return 1;
}
public int getNb2(){
//specify what must happen
return 2;
}
}
public class SubClass extends SuperClass{
//you can override the implementation
@Override
public int getNb2(){
return 3;
}
}
Subclass s = new SubClass();
s.getNb(); //returns 1
s.getNb2(); //returns 3
SuperClass sup = new SuperClass();
sup.getNb(); //returns 1
sup.getNb2(); //returns 2※CVCS,DVCS 차이점
:VCS는 Version Control System의 약자 버전관리시스템을 뜻한다.
1.CVCS(Centrailzed Version Control System) - 중앙집중식 버전관리시스템 예:SVN
:파일은 관리하는 서버가 따로 있다. 중앙서버에 오류가 생길 경우 파일을 올리거나 다운받을수 없다.
또한 중앙서버의 하드디스크에 문제가 생기면 모든변경이력을 잃게 된다.
2.DVCS(Distributed Version Control System) - 분산 버전관리시스템 예:GIT
:CVCS의 단점을 보완한 시스템으로써 CVCS처럼 중앙서버를 구성하긴 하지만 개인의 로컬컴퓨터도 하나의 서버로 작동이 가능하다. 속도도 빠른편이라고 함.
※공인 ip,사설 ip,고정 ip,유동 ip
(참조:https://blog.naver.com/grang21/220015219375)
1.공인 IP는 ICANN. 인터넷 진흥원(KISA)등의 IP 주소 할당 공인기관에서 할당한 인터넷 상에서 사용할 수 있는 IP주소를 말합니다.
2.사설 IP는 내부 네트워크 ( 예, 공유기 내부 네트워크 ) 상에서만 사용되는 주소로 인터넷상에서는 사용할 수 없는 IP주소입니다.(원격접속 X)
3.고정 IP는 IP를 고정으로 지정해서 사용하는 방법입니다. 원격접속이 가능하고 서버를 돌릴때도 고정IP로 되있어야 합니다. 하지만 보안에는 취약합니다.
4.유동 IP는 컴퓨터를 재부팅할때마다 새로운 IP를 할당받는 방식을 말합니다.
ex) 인터넷 -(공인IP)- 공유기 -(사설IP)(고정IP또는 유동IP)- 각 사용자들(일반사용자)
ex) 인터넷 -(공인IP&고정IP) - 서버
ex) 인터넷 -(공인IP&유동IP) - 일반사용자
공인IP - 외부아이피 // 사설IP - 내부아이피

※HTML, CSS, JavaScript (정적인 서비스를 제공하는 언어)
1.HTML: 정보/구조/몸
2.CSS: 디자인/표현/옷
3.JavaScript: 웹브라우저, html 제어/동작/움직임
※PHP,JSP,ASP 차이점(동적인 서비스를 제공하는 언어)
1.PHP:어떤 운영서버에서도 작동가능, 보안에 취약 C언어 기반 속도빠름 , MYSQL 무료
2.JSP:어떤 운영서버에서도 작동가능, JAVA 기반
3.ASP:ASP를 이용하기 위해서는 iis웹서버 설치(윈도우만사용가능) C#,C++ 기반
※Apahce (Web Server),Tomcat (WAS),iis 차이
(참조:https://okky.kr/article/243427)
1.Web Server - 정적데이터
:HTML 문서같은 정적인 데이터를 처리하는 서버 WAS보다 빠르고 안정적이다.
클라이언트로 부터 요청을 받아 요청한 것을 넘겨주는 일을 하는 것
웹서버는 정적인 페이지만 서비스 함
웹서버는 단지 파일을 찾아서 있는 그대로 클라이언트에게 넘겨주는 일만 함
요청한 자료를 찾지 못 하면 404 Not Found 메시지를 보냄
동적인 컨텐츠 생성이 불가능 하다.
Apache는 유명한 오픈 소스 웹서버
Web Server 종류:IIS, apache, tMax, WebtoB
2.WAS (Web Server + Web Container) - 동적데이터
:동적인 데이터를 처리하는 서버 데이터베이스와 연결하여 데이터 조작을 할 때 사용한다.
Web Container = JSP와 서블릿을 실행시킬 수 있는 소프트웨어를 웹 컨테이너라고 한다.
*Servlet 과 JSP
1)Servlet : WAS 를 통해 컴파일 된 후 메모리에 적재되어 클라이언트의 HTTP Get, Post 등의 요청을 처리하는
자바 프로그램
- JAVA코드 내부에 HTML코드를 삽입하는 형식
2)JSP : Servlet의 단점을 보완하기 위해서 나옴, HTML코드 내부에 JAVA코드를 삽입하는 형식
WAS종류:tomcat, tMax jeus, BEA Web Logic, IBM Webspere, JBOSS,Bluestone, Gemston, inprise, Oracle, PowerTier,Apptivity,silverStream
3.IIS (Internet Information Service) - Web Server(정적데이터)
:윈도우 OS에서만 사용가능함. ASP의 환경이 MS계열 서비스라면 WAS의 기능을 담당하는 부분이 있어 별도의 WAS가 필요하지않다.
!!Web Server 와 WAS를 기능을 나눠서 쓰는 이유는 부하를 줄이기 위한 분산처리를 하기 위함이다.
※웹(WEB) 인터넷 구동원리(참조:http://dancinghacker.tistory.com/125)

※java 메모리 구조
(참조:https://atin.tistory.com/625)

설명: Hello.java 파일이 JAVA 컴파일러를 통해서 Hello.class로 변환된다.(바이트코드)
Class loader는 바이트코드를 메모리에 적재하는 기능
Execution Engine는 바이트코드를 해석하는 기능을 한다.
Runtime Data Area는 OS에서 할당받은 메모리 공간이다.
*Runtime Data Area
1.Method Area - 모든 Thread가 공유하는 메모리영역이다. JVM이 읽어들인 클래스와 인터페이스에 대한 상수풀,필드,멤버변수,클래스변수,생성자,메소드가 저장되는 공간
2.Stack - 메서드 호출시 스택프레임 생성, 메서드 안에서 생성된 값들을 임시저장, 메서드 수행이 끝나면 삭제
3.Heap - new 연산자로 생성된 객체와 배열을 저장하는 공간, 런타임이 동적으로 할당하는 공간(GC관리)
4.Native Method - 자바언어 외에 다른언어에서 제공되는 메서드가 저장되는 공간
5.PC Register - 현재 실행되는 부분의 명령과 주소를 저장